 Home
Home
[딜사이트 권녕찬 기자] 인공지능(AI) 인프라의 핵심 병목으로 지적돼 온 GPU(그래픽처리장치) 메모리 구조 한계를 순수 국산 기술로 극복할 수 있을지 주목된다. 국내 반도체 팹리스 기업 '멤레이'는 AI 데이터가 폭증하는 환경에서 GPU 연산 능력을 뒷받침해 데이터 처리 속도를 높이는 '바이트플래시(ByteFlash)' 기술로 차세대 AI 인프라 시장의 게임체인저가 되겠다는 포부를 밝혔다.
코스닥 상장사 '멤레이비티'(구 율호)는 17일 서울 여의도에서 멤레이의 기업설명회를 주최했다. 멤레이는 GPU·스토리지 인터페이스와 데이터 경로에 대한 원천기술을 보유한 반도체 팹리스 스타트업이다.
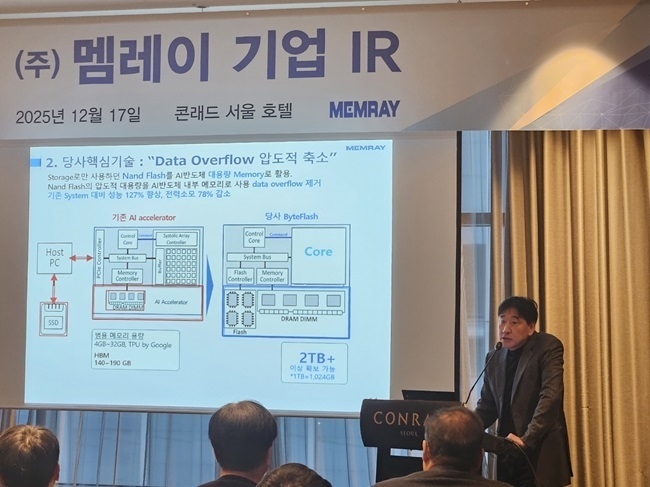
이날 멤레이는 GPU 연산 속도를 유지하면서 GPU가 접근할 수 있는 메모리 범위를 대폭 확장하는 차세대 메모리 기술 '바이트플래시'를 공개했다.
현재 AI 연산의 중심에 있는 GPU는 초고속 처리를 위해 HBM(고대역폭메모리)을 사용하고 있다. HBM은 GPU 연산 유닛과 밀접하게 연결돼 가장 빠른 메모리로 평가받지만, 연산 성능이 고도화될수록 스토리지로부터 데이터를 불러오는 대기시간이 전체 성능을 제약하는 구조적 한계가 드러나고 있다. AI 시대 GPU가 처리해야 할 데이터 양이 기하급수적으로 늘어나는 점도 부담 요인이다.
AI 모델이 대형화될수록 GPU가 요구하는 메모리 용량은 급격히 증가하고 있지만, 이를 HBM만으로 감당하기에는 비용과 공급 측면에서 한계가 동시에 커지고 있다는 지적이 나온다.
멤레이가 자체개발한 '바이트플래시'는 이 같은 환경에서 GPU 연산 속도를 저하시키지 않으면서도 접근 가능한 메모리 영역을 확장하는 데 초점을 맞춘 기술이다. GPU 연산 파이프라인을 유지한 채 필요한 데이터를 지속적으로 공급하는 방식으로 설계됐다.
특히 HBM에 준하는 고속 데이터 교환 성능을 유지하면서도 전력 소모를 획기적으로 낮춘 고속·저전력 확장 메모리라는 점이 특징이다. GPU 입장에서는 연산 도중 데이터를 기다리는 시간이 줄어들고, 더 큰 AI 모델과 데이터셋을 연속적으로 처리할 수 있는 구조가 가능해진다는 설명이다.
멤레이 측은 기술 개발 과정에서 GPU 연산 파이프라인을 끊지 않는 수준의 대역폭과 지연 특성을 검증했으며, 이를 통해 기존 구조 대비 전력 효율과 시스템 활용도를 동시에 개선할 수 있는 가능성을 확인했다고 밝혔다. 이는 AI 서버와 데이터센터에서 핵심 지표로 꼽히는 연산 효율과 처리량을 직접적으로 끌어올릴 수 있다는 의미다.
바이트플래시는 글로벌 AI 반도체 업계가 주목하고 있는 차세대 메모리 개념인 'HBF(High Bandwidth Flash Memory)'와도 같은 흐름에 있다. HBF는 HBM의 속도를 유지하면서 GPU가 활용할 수 있는 메모리 자원을 하드웨어적으로 확장하는 방식이다.
반면 바이트플래시는 소프트웨어 기술을 통해 플래시 메모리를 D램(DRAM)처럼 구현할 수 있어, HBF 대비 제조 단가가 크게 낮고 시스템 구성의 유연성이 높다는 점을 강점으로 내세운다.
멤레이비티 관계자는 "바이트플래시 기술이 상용화되면 AI 학습·추론 서버와 대규모 데이터센터에서 GPU 연산 효율을 유지한 채 메모리 구조를 재편할 수 있는 현실적인 선택지가 될 것으로 기대한다"며 "특히 초대형 언어모델(LLM) 등 연산 중단 없이 대량의 데이터를 지속적으로 처리해야 하는 것처럼 급속도로 성장 중인 AI 시장에서 파급력이 클 것으로 예상된다"고 전했다.
이어 "AI 인프라 경쟁은 이제 단순히 GPU 연산 속도를 향상하는 경쟁을 넘어 GPU가 얼마나 큰 메모리 스토리지에 의해 지원을 받고, 이 대용량 스토리지와 병목 현상 없이 얼마나 많은 정보를 빠르게 교환할 수 있게 할 것이냐에 경쟁이 집중될 것"이라며 "GPU 연산 흐름을 유지하면서 메모리 구조를 확장할 수 있는 바이트플래시 기술은 차세대 AI 인프라의 '게임체인저'로 자리매김할 수 있을 것으로 기대한다"고 덧붙였다.
ⓒ새로운 눈으로 시장을 바라봅니다. 딜사이트 무단전재 배포금지
















